企业AI数字形象交互系统
系统简介
本系统依托语音处理、大语言模型、知识增强等技术,实现自然化的语音交互与拟人化的数字人表现。
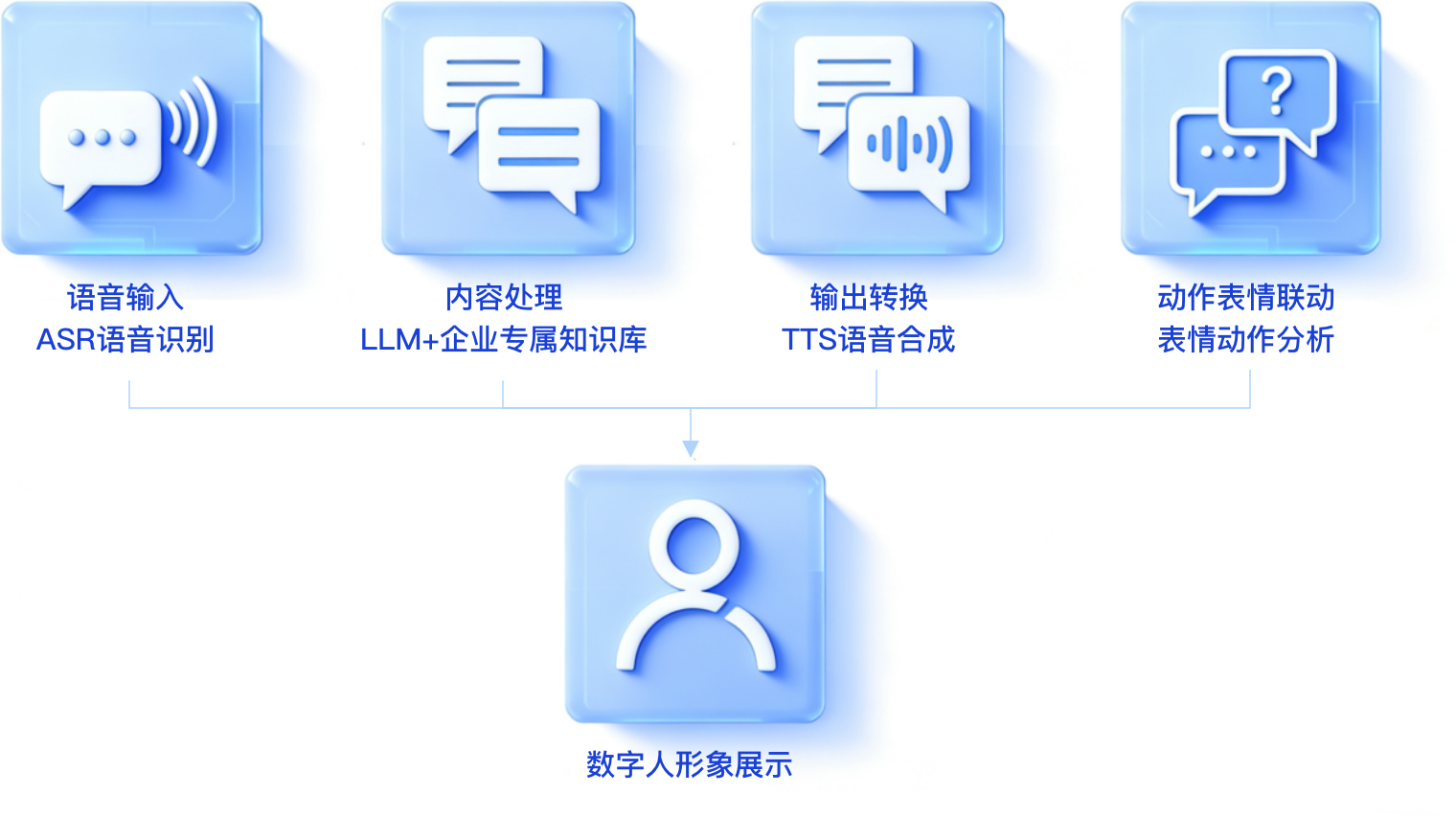
系统特点

交互自然化:多模态沉浸式语音交互
以语音为核心交互载体,通过 ASR(语音识别)与 TTS(语音合成)的协同,实现 “语音输入 - 文本转换 - 语音输出” 的流畅衔接,语音识别精准度、合成语音的自然度贴近真人沟通;同时结合数字人的动作、表情同步表现,打破纯语音交互的单调感,让用户获得更接近真实人际交流的体验。
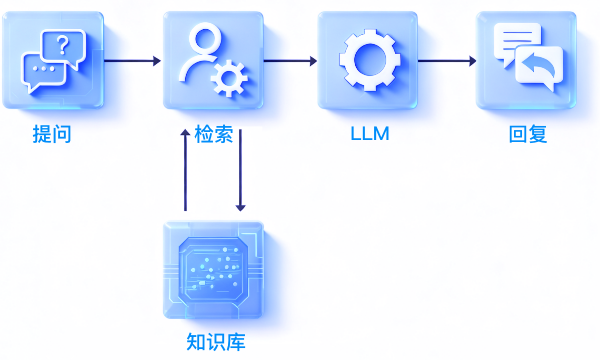
知识专属化:企业信息精准赋能
依托 “RAG + 企业专属知识库” 的组合,LLM 的回复内容并非通用信息,而是基于企业自有数据生成,确保交互内容与企业实际需求高度匹配,避免通用大模型回复的信息偏差。

表现拟人化:数字人动作表情协同
通过表情动作分析模块,数字人可同步匹配语音内容的情绪与语义,输出对应的肢体动作、面部表情,强化数字人的 “拟人属性”,提升交互的沉浸感与亲和力。
系统功能
-

企业人格化形象定制与动态适配
支持根据企业文化调性定制数字形象的外观、语言风格、动作表情特征;同时可根据交互场景自动切换形象的表现模式。
-

跨媒介内容联动展示
具体说明:数字形象在交互过程中,可同步联动企业的多媒体内容,通过 “语音讲解 + 内容同步展示” 的形式呈现信息;支持用户在交互中主动触发内容查看
-

用户交互行为分析与体验优化
系统自动采集用户与数字形象的交互数据,通过数据分析模块生成 “交互体验报告”,识别用户偏好的交互方式、信息类型;同时可基于分析结果,自动优化数字形象的回复逻辑、内容优先级.